Introduction
CLAM, the Computational Linguistics Application Mediator, allows you to quickly and transparently transform your Natural Language Processing application into a RESTful webservice, with which automated clients can communicate, but which at the same time also acts as a modern webapplication with which human end-users can interact. CLAM takes a description of your system and wraps itself around the system, allowing clients or users to upload input files to your application, start your application with specific parameters of their choice, and download and view the output of the application. While the application runs, users can monitor its status.
CLAM is set up in a universal fashion, making it flexible enough to be wrapped around a wide range of applications that have a command line interface. These applications are treated as a black box, of which only the parameters, input formats, and output formats need to be described. The applications themselves need not be network-aware in any way, nor aware of CLAM, and the handling and validation of input can be taken care of by CLAM.
CLAM is entirely written in Python, runs on UNIX-derived systems, and is available as open source under the GNU Public License (v3). It is set up in a modular fashion, and offers an API, and as such is easily extendable. CLAM communicates in a transparent XML format, and uses client-side XSL transformation to offer a full modern web-interface for human end users.
The kind of applications that CLAM is originally intended for are Natural Language Processing applications, usually of a kind that do some processing on a text corpus. This corpus (any text file) can be uploaded by the user, or may be pre-installed for the webservice. The NLP application is usually expected to produce a certain output, which is subsequently made available through the webservice for viewing and downloading. CLAM can, however, just as well be used in fields other than NLP.
The CLAM webservice is a RESTful webservice [Fielding2000], meaning it uses the HTTP verbs GET, POST, PUT and DELETE to manipulate resources and returns responses using the HTTP response codes and XML. The principal resource in CLAM is called a project. Various users can maintain various projects, each representing one specific run of the system, with particular input data, output data, and a set of configured parameters. The projects and all data is stored on the server.
The webservice responds in the CLAM XML format. An associated XSL stylesheet [XSLT] can directly transform this to xhtml in the user’s browser, thus providing a standalone web application for human end-users.
The most notable features of CLAM are:
RESTful webservice – CLAM is a fully RESTful webservice
Webapplication – CLAM is also provides a generic web user interface for human end-users.
Extensible – Due to a modular setup, CLAM is quite extensible
Client and Data API – A rich Python API for writing CLAM Clients and system wrappers
Authentication – A user-based authentication mechanism through HTTP Digest and/or HTTP Basic is provided. Morever, OAuth2 is also supported for delegating authentication
Metadata and provenance data – Extensive support for metadata and provenance data is offered
Automatic converters – Automatic converters enable conversion from an auxiliary format into the desired input format, and conversion from the produced output format into an auxiliary output format
Viewers – Viewers enable web-based visualisation for a particular format. CLAM supports both built-in python-based viewers as well as external viewers in the form of external (non-CLAM) webservices.
Predefined datasets – Service providers may optionally predefine datasets, such as large corpora
Batch Processing – CLAM’s default project paradigm is ideally suited for batch-processing and the processing of large files. The background process may run for an undefined period
Actions – CLAM’s action paradigm is a remote-procedure call-mechanism in which you make available actions (any script/program or Python function) on specific URLs.
Constraints and Input Validation – *CLAM has a mechanism to actively validate the files the user inputs, and apply constraints
to them*.
In publication pertaining to research that makes use of this software, a citation should be given of: “Maarten van Gompel (2014). CLAM: Computational Linguistics Application Mediator. Documentation. LST Technical Report Series 14-03.”.
CLAM is open-source software licensed under the GNU Public License v3, a copy of which can be found along with the software.
Fielding (2000). Architectural Styles and the DEsign of Network-based Software Architecture. Doctoral Dissertation. University of California, Irvine. (HTML)
Clark (1999). XSL Transformations (XSLT) Version 1.0. W3C Recommendation. http://www.w3.org/TR/xslt
Technical details
CLAM is written in Python [python], and is built on the Flask framework [flask]. It can run stand-alone thanks to the built-in webserver; no additional webserver is needed to test your service. In production environments, it is however strongly recommended that CLAM is integrated into a real webserver. Supported are: Apache, nginx or lighthttpd, though others may work too.
The software is designed for Unix-based systems (e.g. Linux or BSD) only. It also has been verified to run on Mac OS X as well. Windows is not supported.
Python Software Foundation. Python Language Reference. Available at https://www.python.org
Intended Audience
CLAM and this documentation are intended for 1) service providers; people who want to build a CLAM Webservice around their tool and/or people wanting to set up existing CLAM services on their server, and 2) webservice users; people who want to write automated clients to communicate with CLAM webservices.
On the part of these users, a certain level of technical expertise is required and assumed, such as familiarity with UNIX/Linux systems, software development (programming) and system administration.
This documentation is split into two parts: a chapter for service providers, people who want to build a CLAM Webservice around their tool, and a chapter for service clients, users wanting to write automated clients to communicate with the aforemented webservice.
This documentation is not intended for end users using only the web application interface.
Architecture
CLAM has a layered architecture, with at the core the command line application(s) you want to turn into a webservice. The application itself can remain untouched and unaware of CLAM. The scheme in the figure below illustrates the various layers. The workflow interface layer is not provided nor necessary, but shows a possible use-case.
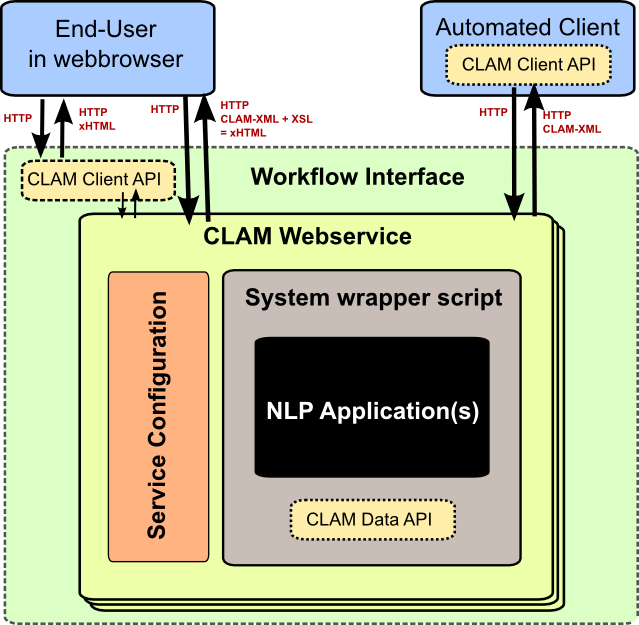
The CLAM Architecture
CLAM presents two different paradigms for wrapping your script or application. You may use either or both at the same time.
Project Paradigm – Users create projects, upload files with optional parameters to those projects, and subsequently start the project, optionally passing global parameters to the system. The system may run for a long time and may do batch-processing on multiple input files.
Action Paradigm – This is a more limited and simple remote-procedure call mechanism. Users interact in real-time with the service on specific URLs, passing parameters, and obtaining a single result. Unlike the project paradigm, this is not suitable for complex operations on big-data.
A CLAM webservice needs the following three components from the service developer:
A wrapperscript` for your command line application;
A command line application (your NLP tool)
The wrapper script is not strictly mandatory if the command line application can be directly invoked by CLAM. However, for more complex applications, writing a wrapper script is recommended, as it offers more flexibility and better integration, and allows you to keep the actual application unmodified. The wrapper scripts can be seen as the “glue” between CLAM and your application, taking care of any translation steps.
Note that wrapper scripts in the action paradigm are more constrained, and there may be multiple wrapper scripts for different actions.
Interface
Though CLAM is a RESTful webserivce, it has a fully client-side interface for human-end users. Some screenshots can be found below:
Table of Contents
- Introduction
- Installation
- Getting Started
- Service configuration
- Wrapper script
- Data API
- Examples
- Data API Reference
AbstractConverterAbstractMetaFieldActionAuthRequiredAuthenticationRequiredBadRequestCLAMDataCLAMFileCLAMInputFileCLAMMetaDataCLAMOutputFileCLAMProvenanceDataConfigurationErrorConstraintCopyMetaFieldForbidMetaFormatErrorForwarderHTTPErrorInputSourceInputTemplateNoConnectionNotFoundOutputTemplateParameterConditionParameterErrorParameterMetaFieldPermissionDeniedProfileProgramRawXMLProvenanceDataRequireMetaServerErrorSetMetaFieldTimeOutUnsetMetaFieldUploadErrorbuildarchive()escape()escapeshelloperators()getclamdata()getformats()loadconfig()loadconfigfile()parsexmlstring()processhttpcode()processparameter()processparameters()profiler()resolveconfigvariables()resolveinputfilename()resolveoutputfilename()sanitizeparameters()shellsafe()unescapeshelloperators()
- Deployment in production
- Clients
- Troubleshooting
- RESTful API specification
Running a test webservice
If you installed CLAM using the above method, then you can launch a clam test webservice using the development server as follows:
$ clamservice -H localhost -p 8080 clam.config.textstats
Navigate your browser to http://localhost:8080 and verify everything works
Note: It is important to regularly keep CLAM up to date as fixes and improvements are implemented on a regular basis. Update CLAM using:
$ pip install -U clam
Installing a particular clam webservice for production use
When installating a particular CLAM webservice on a new server, you typically start with creating a host-specific external configuration file that specifies all the paths and urls specific to thw new server. Of interest is in particular the ROOT path, which is where user data will be stored, this directory must exist and be writable by the webserver.
For production, it is strongly recommended to embed CLAM in Apache or nginx. This is the typically task of a system administrator, as certain skills are necessary and assumed. All this is explained in detail in the section Deployment in production.